IPv4
От 0.50$ за 1 шт. 38 стран на выбор, срок аренды от 7 дней.
IPv4
От 0.50$ за 1 шт. 38 стран на выбор, срок аренды от 7 дней.
IPv4
От 0.50$ за 1 шт. 38 стран на выбор, срок аренды от 7 дней.
IPv6
От 0.07$ за 1 шт. 14 стран на выбор, срок аренды от 7 дней.
ISP
От 1$ за 1 шт. 23 стран на выбор, срок аренды от 7 дней.
Mobile
От 14$ за 1 шт. 18 стран на выбор, срок аренды от 2 дней.
Resident
От 0.70$ за 1 GB. 200+ стран на выбор, срок аренды от 30 дней.
 Австралия
Австралия
 Англия
Англия
 Армения
Армения
 Бельгия
Бельгия
 Болгария
Болгария
 Бразилия
Бразилия
 Германия
Германия
 Гонконг
Гонконг
 Грузия
Грузия
 Индия
Индия
 Индонезия
Индонезия
 Испания
Испания
 Италия
Италия
 Казахстан
Казахстан
 Канада
Канада
 Китай
Китай
 Корея
Корея
 Латвия
Латвия
 Литва
Литва
 Малайзия
Малайзия
 Мексика
Мексика
 Нидерланды
Нидерланды
 Польша
Польша
 Португалия
Португалия
 Россия
Россия
 Румыния
Румыния
 Сингапур
Сингапур
 США
США
 Таиланд
Таиланд
 Турция
Турция
 Украина
Украина
 Финляндия
Финляндия
 Франция
Франция
 Чехия
Чехия
 Швейцария
Швейцария
 Швеция
Швеция
 Южная Африка
Южная Африка
 Япония
Япония
Прокси по целям:
Австралия
Англия
Армения
Бельгия
Болгария
Бразилия
Германия
Гонконг
Грузия
Индия
Индонезия
Испания
Италия
Казахстан
Канада
Китай
Корея
Латвия
Литва
Малайзия
Мексика
Нидерланды
Польша
Португалия
Россия
Румыния
Сингапур
США
Таиланд
Турция
Украина
Финляндия
Франция
Чехия
Швейцария
Швеция
Южная Африка
Япония
Прокси по целям:
Инструменты:
Австралия
Англия
Армения
Бельгия
Болгария
Бразилия
Германия
Гонконг
Грузия
Индия
Индонезия
Испания
Италия
Казахстан
Канада
Китай
Корея
Латвия
Литва
Малайзия
Мексика
Нидерланды
Польша
Португалия
Россия
Румыния
Сингапур
США
Таиланд
Турция
Украина
Финляндия
Франция
Чехия
Швейцария
Швеция
Южная Африка
Япония
Веб-скрапинг стал стратегическим компонентом корпоративных процессов, связанных с аналитикой, конкурентной разведкой, мониторингом цен и генерацией лидов. Для их реализации требуются инструменты для веб-скрапинга, способные обрабатывать большие объемы данных, эффективно работать с сайтами, использующими антибот-защиту и API-ограничения, логировать запросы и ответы API, соответствовать требованиям безопасности и комплаенса.
В этом материале представлен обзор ведущих решений 2026 года, созданных с учетом приоритетов бизнеса: экономической эффективности, защищенности инфраструктуры, гарантий SLA, минимизации простоев и готовности к масштабированию. Цель статьи – помочь компаниям выбрать не просто инструмент, а инфраструктурное решение, обеспечивающее устойчивый, предсказуемый и безопасный доступ к веб-данным.
Инструменты для сбора данных различаются по архитектуре, уровню контроля и степени готовности к интеграции в корпоративные процессы. Различают следующие виды:
От выбора платформы для веб-скрапинга зависит полнота полученной информации, эффективность распределения бюджета и точность управленческих решений. Ошибка на этом этапе ведет к потерям времени и ресурсов, тогда как верно выбранная технология гарантирует устойчивость процессов и конкурентное преимущество. Ниже – ключевые критерии, на которые стоит опираться при оценке решений.
Также важно учитывать технические навыки специалистов, которые будут использовать инструменты для скрапинга данных. От их подготовки зависит не только корректность настройки и интеграции решения, но и эффективность всего процесса.
Ниже представлены лучшие инструменты для веб-скрапинга и сбора данных, эффективность которых подтверждена независимыми обзорами и пользовательскими рейтингами по критериям надежности, функциональности и соответствия корпоративным стандартам.
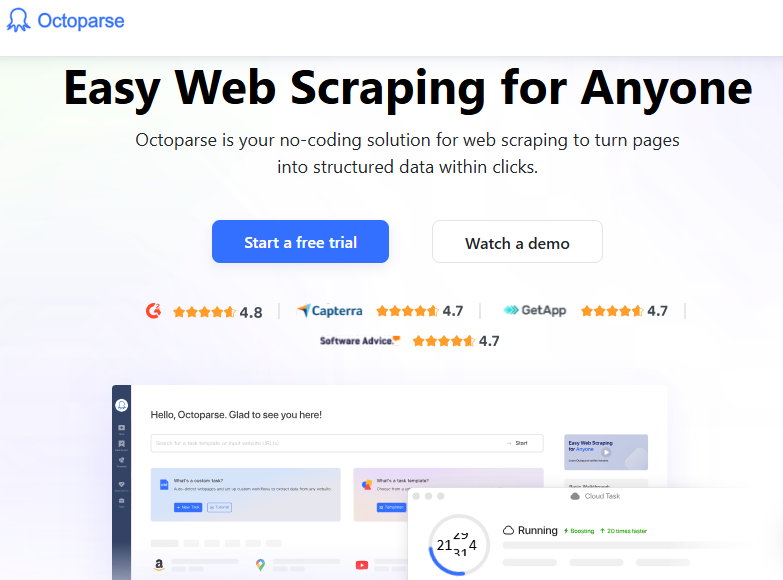
Octoparse – гибридная no-code платформа для веб-скрапинга, объединяющая локальное приложение и облачные ресурсы.
Ключевые функции:
Платформа отличается низким порогом входа: интуитивно понятный визуальный интерфейс упрощает создание сценариев без участия разработчиков, что упрощает тесты и пилоты.
Производительность зависит от числа параллельных задач. 3 предусмотрены в плане Standard, 20 – в Professional, свыше 40 – в Enterprise. Этого достаточно для малого и среднего бизнеса, но может быть недостаточно для корпоративных проектов, где требуется более высокая нагрузка и гарантии SLA.
Для работы с механизмами анти-скрапинга предусмотрены ротация IP, прокси и обработка CAPTCHA, однако отсутствует гибкая настройка прокси-пулов и собственных IP-листов, что ограничивает компании с требованиями к разнообразной географии.
Модель тарификации основана на объеме запросов: чем выше лимит, тем шире спектр задач, которые можно решать.
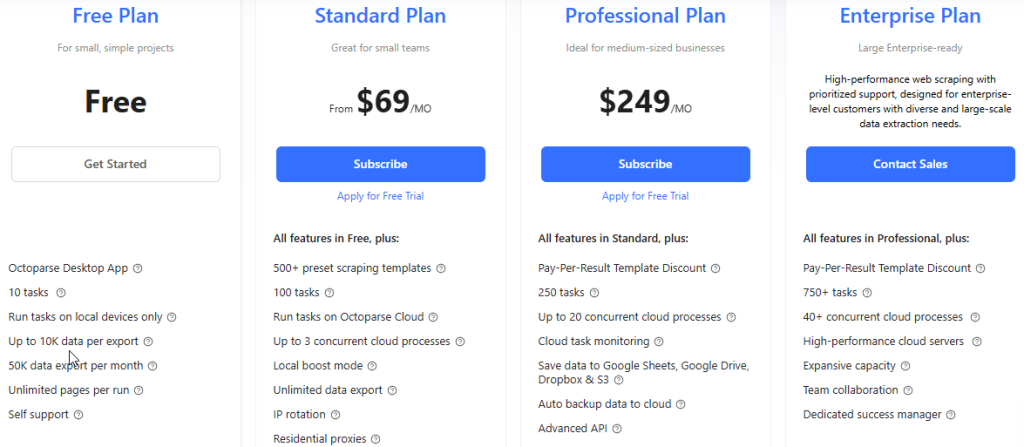
Базовый план подходит для тестирования и небольших проектов, стандартный и профессиональный – для системного сбора и аналитики, а корпоративный – для масштабных интеграций и высоконагруженных пайплайнов.

Bright Data – enterprise-платформа для веб-скрапинга и управления прокси-инфраструктурой.
Ключевые функции:
Инструмент рассчитан на компании, которым требуется гибкость и масштаб: от быстрого прототипирования до промышленного веб-скрапинга. Наличие no-code интерфейса снижает порог входа, а SDK и выделенные ресурсы позволяют строить распределенные пайплайны без ограничений по объему запросов. Для корпоративных клиентов предусмотрены SLA и приоритетная техническая поддержка.
Модель тарификации основана на объеме собираемой информации и уровне используемой прокси-сети: чем выше требования к стабильности и скорости, тем выгоднее стоимость при масштабных нагрузках.

Тарифы Bright Data охватывают весь цикл задач – от пилотных проектов до корпоративных интеграций. “Pay-as-you-go” подходит для тестирования и разовых выгрузок. Базовый пакет – для регулярного мониторинга e-commerce-рынков и обновления товарных фидов. Бизнес обеспечивает централизованный сбор рыночных данных и построение BI-аналитики, а Премиум – предназначен для потоковой обработки, генерации датасетов и интеграции в корпоративные процессы.

ParseHub – no-code платформа для веб-скрапинга, совмещающая удобство десктопного интерфейса с возможностями облачного выполнения задач.
Ключевые функции:
Платформу отличает простота внедрения: визуальный интерфейс, подробная документация и обучающие материалы, в том числе и бесплатные онлайн-курсы по веб-скрапингу от Parsehub Academy, снижают порог входа, делая сервис удобным решением для небольших команд и перспективных проектов.
Производительность ограничена тарифом – числом параллельных процессов и страниц за запуск. Для крупных корпоративных сценариев доступен ParseHub Plus с возможностью масштабирования и технической поддержки со стороны команды разработчика.
Несмотря на наличие ротации IP и встроенных прокси-пулов, платформа не предусматривает гибкой настройки собственной сетевой инфраструктуры, что может быть критично для компаний с требованиями к геотаргетингу и контролю трафика.
Модель тарификации ParseHub основана на объеме выгружаемых данных и числе параллельных процессов. Базовые планы подходят для обучения и регулярного мониторинга контента, а профессиональные – для e-commerce и маркетинговых исследований, анализа отзывов, SEO-аудита и конкурентного трекинга.


Oxylabs Web Scraper API – облачное решение для промышленного веб-скрапинга, ориентированное на компании с высокими требованиями к объему, отказоустойчивости и гибкости интеграции.
Ключевые функции:
Развертывание интеграционного сервиса занимает минимальное время: создание аккаунта, настройка эндпоинтов и подключение к системе обработки информации. Для продакшн-интеграций необходим опыт в REST, сетевой инфраструктуре и управлении потоками данных. Решение легко встраивается в DevOps- и DataOps-экосистемы, обеспечивая воспроизводимость и управляемость процессов.
Инфраструктура Oxylabs рассчитана на миллионы успешных запросов в месяц и стабильную работу под нагрузкой: поддерживаются постоянный data-ingestion, real-time-обновления и адаптивные лимиты RPS в зависимости от тарифа.
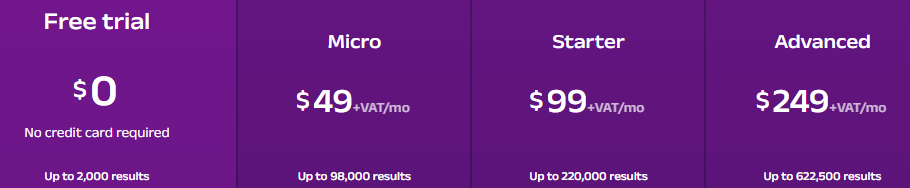
Базовые планы подходят для пилотных задач и e-commerce-мониторинга, профессиональные – для автоматизации аналитических процессов и SaaS-интеграций, а корпоративные – для потокового сбора и real-time обновлений в высоконагруженных системах.

Scrapy – открытый фреймворк на Python для веб-скрапинга и краулинга, предназначенный для DevOps и Data-инженеров.
Ключевые функции:
Scrapy требует продвинутых знаний Python и понимания сетевой архитектуры. Порог входа выше, чем у no-code решений, однако фреймворк обеспечивает полный инженерный контроль над процессом. Он легко масштабируется горизонтально: можно запускать несколько скраперов одновременно и распределять нагрузку между серверами.
Решение интегрируется с корпоративными системами через API и настраиваемые сценарии взаимодействия, поддерживает webhooks и REST-интерфейсы. Безопасность и надежность обеспечиваются за счет внешних прокси, IP-ротации и собственных обработчиков сессий.
Фреймворк распространяется под лицензией BSD (Open Source) и не имеет ограничений по масштабу, что делает его подходящим для корпоративных ETL-конвейеров.

Beautiful Soup – Python-библиотека для разбора HTML и XML-файлов, используемая в DevOps и Data-инженерных командах для извлечения, очистки и структурирования веб-данных.
Ключевые функции:
Невзирая на ориентированность на Python-разработчиков, библиотека отличается низким порогом входа и эффективна при работе с отдельными страницами или небольшими наборами данных. Она не предназначена для многопоточности и высоких нагрузок, но масштабируется в связке с инструментами вроде Scrapy, Dask, Spark или оркестраторами Airflow и Kubernetes.
Библиотека не выполняет сетевые запросы, но легко интегрируется в инфраструктуру через Python-скрипты и REST-обертки. Применяется совместно с API и хранилищами (PostgreSQL, Snowflake, BigQuery).
Решение распространяется по модели Open Source без ограничений по масштабу.
Apify – облачный скрапер уровня Enterprise для скрапинга и автоматизации веб-процессов. Сочетает простоту low-code-интерфейсов с гибкостью кастомных сценариев.
Ключевые функции:
Apify обеспечивает быстрый старт и гибкую настройку рабочих процессов. Готовые акторы из Apify Store можно комбинировать с собственными сценариями, создавая решения под конкретные бизнес-задачи.
Платформа поддерживает тысячи параллельных процессов с автоматическим масштабированием и балансировкой нагрузки. Для корпоративных пользователей предусмотрены выделенные кластеры, SLA и приватные облака для задач с повышенными требованиями к стабильности.
Для Enterprise-клиентов доступны приватные IP-пулы и логирование по стандартам комплаенса.
Модель тарификации Apify основана на Compute Units (CU) – единицах вычислительных ресурсов, которые отражают фактическое потребление процессорного времени, памяти и сетевых операций. Такая схема делает оплату гибкой: компании платят не за количество запросов, а за реально использованные мощности.


ScrapingBee – интеграционный сервис для веб-скрапинга, ориентированный на автоматизацию, прокси-ротацию и работу с динамическим контентом.
Ключевые функции:
ScrapingBee предлагает максимально простой старт: регистрация, получение API-ключа и запуск первого запроса. Управление полностью выполняется через API, что исключает необходимость настройки прокси-сетей и браузеров. Решение оптимально для аналитиков, маркетологов и разработчиков, которым требуется “скрапинг как сервис” без сложной инфраструктуры.
Платформа поддерживает до миллионов API-вызовов в месяц и свыше 200 параллельных запросов. Для крупномасштабных сценариев доступны Enterprise-планы с выделенными ресурсами и SLA.
ScrapingBee использует модель оплаты по количеству API-кредитов – чем выше тариф, тем больше запросов и выше уровень обслуживания.
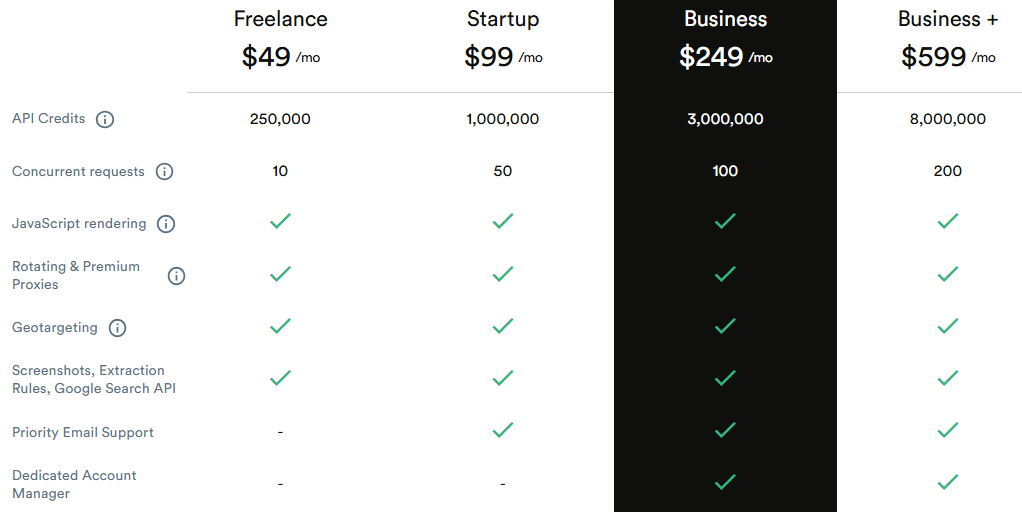

Browse AI – решение для автоматизированного сбора и мониторинга веб-данных, ориентированное на бизнес-команды, которым требуется быстрое развертывание процессов без DevOps-нагрузки и настройки инфраструктуры.
Ключевые функции:
Анализируя инструменты для веб-скрапинга, стоит отметить, что Browse AI выделяется простотой развертывания и минимальными требованиями к настройке инфраструктуры. Платформа запускается за считанные минуты: создается робот, задается расписание и подключаются корпоративные системы. Архитектура поддерживает параллельное выполнение сотен процессов, автоматический скейлинг и балансировку ресурсов, обеспечивая стабильную работу при росте нагрузки. Для проектов с высокими SLA предусмотрены выделенные вычислительные ресурсы и расширенные параметры отказоустойчивости.
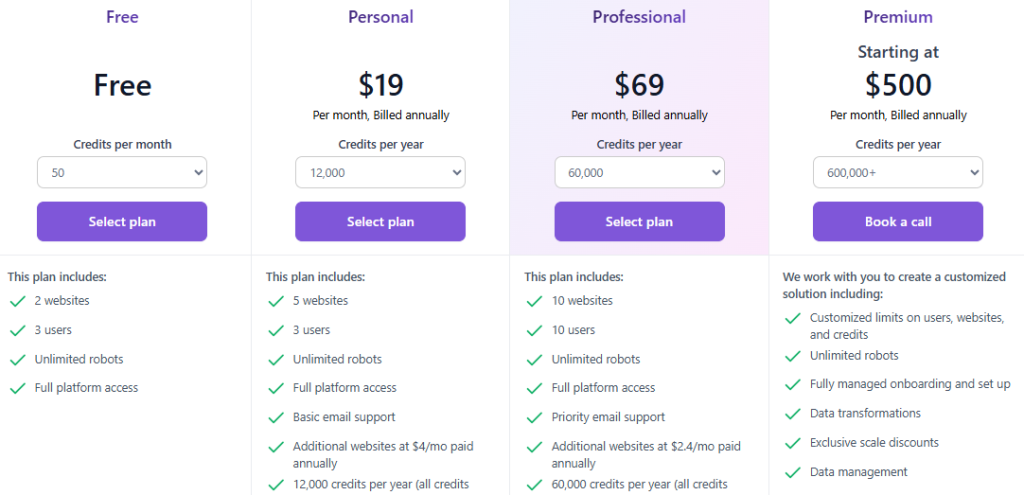
Модель тарификации основана на credits: один кредит соответствует одному запуску робота или мониторингу страницы. Такой подход обеспечивает прозрачность и точный контроль затрат, так как компании оплачивают фактическое использование ресурсов.

Web Scraper.io – гибридная платформа для визуального веб-скрапинга, объединяющая браузерное расширение и облачный сервис Web Scraper Cloud.
Ключевые функции:
Работа начинается с браузерного расширения, где визуально настраиваются сценарии и логика извлечения информации. Дальнейшее выполнение и масштабирование происходят в облачной среде Web Scraper Cloud, которая обеспечивает распределенную обработку, планирование и хранение результатов. Такой подход снижает нагрузку на DevOps-команды и позволяет быстро перейти от прототипов к промышленным решениям.
Инфраструктура платформы поддерживает параллельное выполнение задач, автоматическую ротацию прокси и механизмы повторных попыток для устойчивости при сетевых сбоях. Для защиты реализовано TLS–шифрование. Пользователи базовых тарифов работают в общей среде, а Enterprise-клиенты получают выделенные ресурсы, контроль сетевых политик и расширенные возможности управления через индивидуальные соглашения.
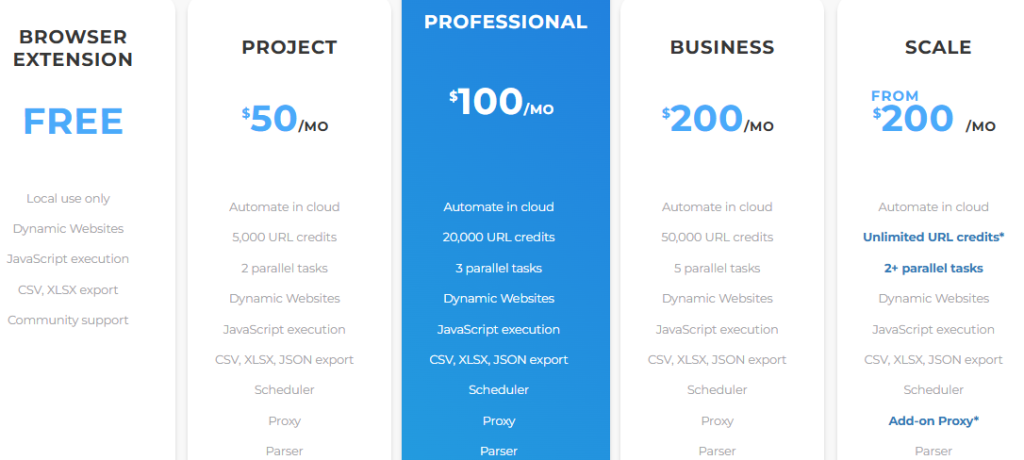
Оплата построена на системе URL-кредитов, где один кредит соответствует одной обработанной странице. Такая модель обеспечивает прозрачность и предсказуемость затрат, что удобно при масштабировании проектов.
Рассмотрев инструменты для веб-скрапинга, можно сделать вывод, что рынок предлагает широкий спектр решений – от простых no-code платформ для малого и среднего бизнеса до API-платформ корпоративного уровня с полным SLA, DevOps-интеграциями и поддержкой динамического контента.
Перед выбором инструмента важно учитывать: будет ли скрапинг разовым или системным, каковы требования к скорости и стабильности, нужен ли контроль за прокси-инфраструктурой, и насколько важна безопасность данных. Сравнительная таблица поможет оценить ключевые параметры представленных решений и подобрать оптимальный инструмент под конкретные задачи и сценарии.
| Инструмент | Тип | Назначение | Масштабируемость | Поддержка прокси и обработка CAPTCHA | Поддержка динамического контента | API / Интеграции (точно) | SLA | Тарификация |
|---|---|---|---|---|---|---|---|---|
| Octoparse | No-code (десктоп + облако) | E-commerce сбор данных, мониторинг цен и контента, маркетинг, конкурентная аналитика | Средняя (до 40+ потоков) | Есть (без гибкой настройки) | JS/AJAX | REST API (Data/Task); экспорт: Google Drive, Amazon S3, Dropbox (v8.7.4+); iPaaS: Zapier, Make | Частично (выше Standart) | По объему/параллельности запуска процессов |
| Bright Data | Enterprise SaaS | Корпоративный сбор и анблокинг данных, BI, финтех, рыночная аналитика | Очень высокая (миллионы соединений) | Есть (собственная сеть прокси и обработка антибот-защиты) | JS/AJAX | Web Unlocker REST API; SDK: JavaScript/Node | Есть | Pay-per-record / по объему собранного материалу |
| ParseHub | No-code (десктоп + облако) | Маркетинг, SEO, анализ отзывов, мониторинг контента, e-commerce трекинг | Средняя (лимиты по процессам/страницам) | Есть (без гибкой настройки) | JS/AJAX | REST API v2 (запуск/статус/выгрузка); Webhooks; экспорт JSON/CSV; iPaaS | Частично (выше Standart) | По страницам и процессам |
| Oxylabs Web Scraper API | API-first SaaS | DataOps и DevOps интеграции, real-time сбор информации, ETL и BI системы | Очень высокая (миллионы запросов) | Есть | JS/AJAX | REST API (realtime/async); SDK: Python; доставка в S3/GCS/OSS; Webhooks | Есть | Pay-per-success |
| Scrapy | Open Source Framework (Python) | Инженерный краулинг, ETL-конвейеры, обработка данных и аналитика | Неограниченная (кластеризация) | Есть | Через Splash/Playwright | Feed exports (CSV/JSON/XML) в S3/FTP/локально; pipelines/hooks | Нет | Бесплатно |
| Beautiful Soup | Open Source Library (Python) | Извлечение и структурирование данных, Python-парсинг, небольшие проекты и исследования | Низкая (через внешние оркестраторы) | Через Python-скрипты | Через Selenium/Playwright | Python API; обычно в связке с Requests/lxml | Нет | Бесплатно |
| Apify | Low-code / SDK SaaS | E-commerce, SEO, real estate, социальные сети, автоматизация и low-code сценарии | Очень высокая (автоскейлинг) | Есть (только для Enterprise) | Через headless-решения | REST API; клиенты: JS/Python; экспорт: S3, BigQuery, GDrive; iPaaS: Zapier/Make/n8n | Есть | Compute Units (CU) |
| ScrapingBee | API SaaS | Автоматизация API-скрапинга, аналитика, маркетинг, разработка без инфраструктуры | Высокая (до ~200 паралл.) | Есть | JS/AJAX | HTML/Browser REST API; SDK: Node; iPaaS: Make/Zapier | Частично (выше Bussines) | По API-кредитам |
| Browse AI | No-code SaaS | Мониторинг и сбор информации без кода, автоматизация бизнес-процессов, отслеживание изменений | Средняя (сотни роботов) | Есть | JS/AJAX | REST API v2; Webhooks; iPaaS: Zapier/Make/n8n | Частично (выше Professional) | По credit-запускам |
| Web Scraper.io | Гибрид (расширение + облако) | Маркетинг, обучение, контент-мониторинг, визуальные сценарии сбора данных | Средняя (облачные задачи) | Есть (только для Enterprise) | JS/AJAX | Web Scraper Cloud REST API; Webhooks; SDK: Node/PHP; экспорт: CSV/XLSX/JSON, Dropbox/Sheets/S3 | По договоренности | По URL-кредитам |
Да, при условии, что инструменты для веб-скрапинга применяются в целях сбора информации из открытых и общедоступных источников. Этичность использования зависит от соблюдения правил конфиденциальности и прозрачности процессов. Подробнее о безопасных практиках скрапинга можно узнать по ссылке.
В 2026 году инструменты для веб-скрапинга будут развиваться в сторону API-first решений, автоматизированных процессов обработки информации в реальном времени и интеграции AI-аналитики. Также ожидается ужесточение требований к SLA, безопасности и прозрачности источников, что укрепит позиции этих технологий в корпоративных экосистемах.
Уровень безопасности инструментов для веб-скрапинга зависит от: прокси и ротации IP-адресов, TLS-шифрования, мониторинга запросов и соблюдения стандартов конфиденциальности (GDPR и SOC2).
 Вконтакте
Вконтакте  Instagram
Instagram  Facebook
Facebook  Telegram
Telegram  OK
OK  Youtube
Youtube  Twitter
Twitter  LinkedIn
LinkedIn  Discord
Discord  Reddit
Reddit  TikTok
TikTok  Key Collector
Key Collector  Яндекс
Яндекс  Google
Google  Lineage 2
Lineage 2  WoW
WoW  Steam
Steam  Origin
Origin  POE
POE  Travian
Travian  Eve Online
Eve Online  Neverlands
Neverlands  New World
New World  Minecraft
Minecraft  Twitch
Twitch  Amazon
Amazon  Ebay
Ebay  Etsy
Etsy  TeamViewer
TeamViewer  Веб-сёрфинг
Веб-сёрфинг 





















































