IPv4
From $0.50 for 1 pc. 38 countries to choose from, rental period from 7 days.
IPv4
From $0.50 for 1 pc. 38 countries to choose from, rental period from 7 days.
IPv4
From $0.50 for 1 pc. 38 countries to choose from, rental period from 7 days.
IPv6
From $0.07 for 1 pc. 14 countries to choose from, rental period from 7 days.
ISP
From $1.35 for 1 pc. 23 countries to choose from, rental period from 7 days.
Mobile
From $14 for 1 pc. 18 countries to choose from, rental period from 2 days.
Resident
From $0.70 for 1 GB. 200+ countries to choose from, rental period from 30 days.
 Armenia
Armenia
 Australia
Australia
 Belgium
Belgium
 Brazil
Brazil
 Bulgaria
Bulgaria
 Canada
Canada
 China
China
 Czech
Czech
 England
England
 Finland
Finland
 France
France
 Georgia
Georgia
 Germany
Germany
 Hong Kong
Hong Kong
 India
India
 Indonesia
Indonesia
 Italy
Italy
 Japan
Japan
 Kazakhstan
Kazakhstan
 Korea
Korea
 Latvia
Latvia
 Lithuania
Lithuania
 Malaysia
Malaysia
 Mexico
Mexico
 Netherlands
Netherlands
 Poland
Poland
 Portugal
Portugal
 Romania
Romania
 Russia
Russia
 Singapore
Singapore
 South Africa
South Africa
 Spain
Spain
 Sweden
Sweden
 Switzerland
Switzerland
 Thailand
Thailand
 Turkey
Turkey
 Ukraine
Ukraine
 USA
USA
Use cases:
Armenia
Australia
Belgium
Brazil
Bulgaria
Canada
China
Czech
England
Finland
France
Georgia
Germany
Hong Kong
India
Indonesia
Italy
Japan
Kazakhstan
Korea
Latvia
Lithuania
Malaysia
Mexico
Netherlands
Poland
Portugal
Romania
Russia
Singapore
South Africa
Spain
Sweden
Switzerland
Thailand
Turkey
Ukraine
USA
Use cases:
Tools:
Company:
About Us:
Armenia
Australia
Belgium
Brazil
Bulgaria
Canada
China
Czech
England
Finland
France
Georgia
Germany
Hong Kong
India
Indonesia
Italy
Japan
Kazakhstan
Korea
Latvia
Lithuania
Malaysia
Mexico
Netherlands
Poland
Portugal
Romania
Russia
Singapore
South Africa
Spain
Sweden
Switzerland
Thailand
Turkey
Ukraine
USA
Web scraping has become a strategic component of enterprise workflows related to analytics, competitive intelligence, price monitoring, and lead generation. To support these use cases, you need data scraping tools capable of handling large data volumes, working effectively with sites that use anti-bot protection and API limits, logging requests and responses, and meeting security and compliance requirements.
This article reviews the leading solutions of 2026 built around business priorities: cost efficiency, infrastructure security, SLA guarantees, minimizing downtime, and readiness to scale. The goal is to help companies choose not just a tool, but an infrastructure solution that ensures stable, predictable, and secure access to web data.
Tools for data scraping differ by architecture, level of control, and readiness to integrate into business processes. The main types are:
Your platform choice affects the completeness of collected information, efficient budget allocation, and decision-making accuracy. A misstep here leads to wasted time and resources, while the right technology ensures process resilience and a competitive edge. Below are the key evaluation criteria.
Also consider the technical skills of the people who will use the data scraping tools. Their competence drives not only proper configuration and integration, but the overall effectiveness of the process.
Below are the top data scraping tools whose effectiveness–based on reliability, functionality, and enterprise-grade standards–has been validated by independent reviews and user ratings.
Octoparse is a hybrid no-code platform combining a local application with cloud resources.
Key features:
The platform has a low barrier to entry: its intuitive visual interface lets you build flows without developers, streamlining tests and pilots.
Performance depends on the number of parallel tasks. Standard includes 3, Professional 20, and Enterprise 40+. This is enough for small and mid-sized businesses but may fall short for corporate projects that need heavier throughput and SLA guarantees.
For platforms with anti-scraping measures, Octoparse supports IP rotation, proxies, and CAPTCHA handling. However, it lacks flexible configuration of proxy pools and custom IP lists, which can limit companies that require diverse geography.
Pricing is based on request volume: the higher the limit, the wider the task scope you can cover.
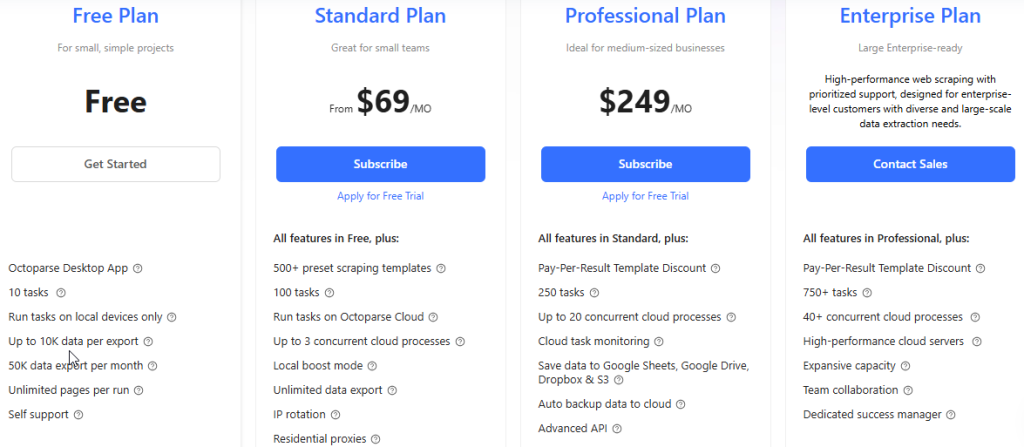
The Basic plan suits tests and small projects; Standard and Professional fit systematic collection and analytics; Enterprise is for large-scale integrations and high-load pipelines.
Bright Data is a business platform for web scraping and proxy-infrastructure management.
Key features:
This tool targets teams that need flexibility and scale–from rapid prototyping to production-grade scraping. The no-code interface lowers the entry barrier, while SDKs and dedicated resources enable distributed pipelines without request-volume constraints. Large customers get SLAs and priority assistance.
Pricing depends on collected data volume and the proxy network level you use: the higher your stability and speed requirements, the more cost-effective it becomes at scale.

Bright Data’s tiers cover the entire lifecycle–from pilots to business integrations. Pay-as-you-go works for testing and one-off exports. Basic fits regular e-commerce market monitoring and feed updates. Business enables centralized market-data collection and BI analytics. Premium is built for streaming, dataset generation, and enterprise integration.

ParseHub is a no-code web-scraping tools that pairs a convenient desktop interface with cloud execution.
Key features:
The platform is easy to adopt: the visual interface, thorough docs, and training materials– including free online courses from ParseHub Academy–lower the learning curve, making it a solid choice for small teams and early-stage projects.
Performance is bounded by your plan–concurrent processes and pages per run. For larger business scenarios, ParseHub Plus adds scaling and support from the vendor’s team.
Despite IP rotation and built-in proxy pools, there’s no deep customization of your own network infrastructure, which can be critical for strict geo-targeting and traffic-control requirements.
Pricing depends on exported data volume and the number of parallel processes. Entry-level tiers suit learning and routine content monitoring; professional tiers fit e-commerce and marketing research, review analysis, SEO audits, and competitive tracking.


Oxylabs Web Scraper API is a cloud solution for production-grade web scraping aimed at companies with high demands for volume, resilience, and integration flexibility.
Key features:
Spin-up time is minimal: create an account, configure endpoints, and hook into your processing stack. For production, you’ll need experience with REST, network infrastructure, and data-flow management. The solution fits seamlessly into DevOps/DataOps ecosystems to ensure reproducible, controllable processes.
Oxylabs’ infrastructure is designed for millions of successful requests per month and stable performance under load: persistent data ingestion, real-time updates, and adaptive RPS limits by plan are supported.
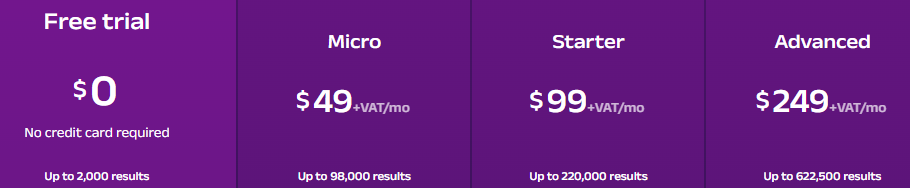
Basic plans fit pilots and e-commerce monitoring; professional tiers target analytics automation and SaaS integrations; enterprise tiers support streaming collection and real-time updates for high-load systems.

Scrapy is an open-source Python framework for web scraping and crawling, designed for DevOps and Data Engineering teams.
Key features:
Scrapy requires strong Python skills and understanding of network architecture. The learning curve is higher than no-code data scraping tools, but the framework gives engineers full control. It scales horizontally: run multiple scrapers in parallel and distribute load across servers.
It integrates with enterprise systems via APIs and custom interactions, supports webhooks and REST endpoints. Security and reliability are achieved with external proxies, IP rotation, and custom session handlers.
Scrapy is released under the BSD license (Open Source) with no scale limits, making it suitable for business ETL pipelines.

Beautiful Soup is a Python library for parsing HTML and XML, used by DevOps and Data Engineering teams to extract, clean, and structure web data.
Key features:
Although developer-oriented, the library has a low barrier to entry and is effective for single pages or small datasets. It’s not designed for multithreading or high loads, but scales when paired with data scraping tools like Scrapy, Dask, or Spark, or orchestrators such as Airflow and Kubernetes.
The library doesn’t perform network requests itself, but plugs neatly into infrastructure through Python scripts and REST wrappers. Commonly used with APIs and data warehouses (PostgreSQL, Snowflake, BigQuery).
It’s Open Source with no inherent scale restrictions.
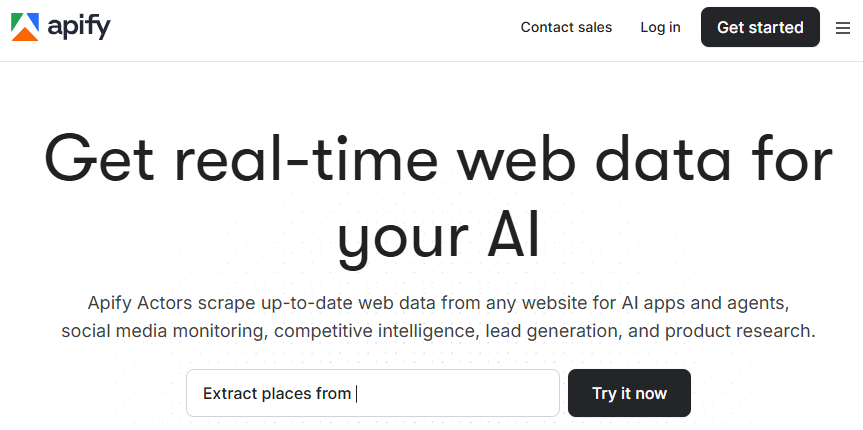
Apify is an enterprise-grade cloud scraper for web scraping and workflow automation. It combines low-code convenience with the flexibility of custom scripts.
Key features:
Apify enables a fast start and flexible process design. You can combine ready-made actors from the Store with your own logic to create solutions tailored to specific business tasks.
The platform supports thousands of parallel processes with automatic scaling and load balancing. Enterprise users can get dedicated clusters, SLAs, and private clouds for heightened stability requirements.
Enterprise customers also have access to private IP pools and compliance-grade logging.
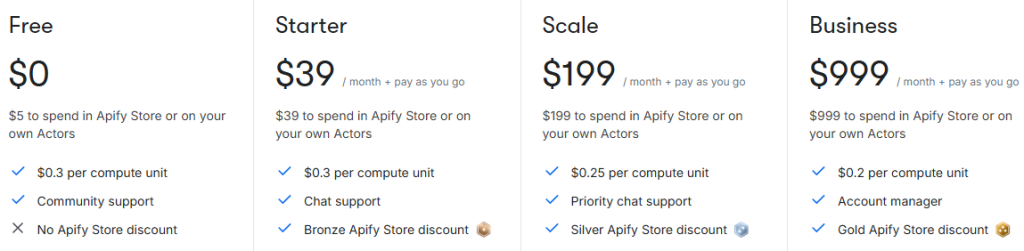
Apify pricing is based on Compute Units (CU)–a measure of compute time, memory, and network operations. This makes billing flexible: companies pay for actual resources used, not raw request counts.

ScrapingBee is an integration-focused web-scraping service oriented toward automation, proxy rotation, and dynamic content.
Key features:
ScrapingBee offers the simplest possible start: sign up, get an API key, send your first request. Management is fully API-driven, so you don’t need to configure proxy networks or browsers yourself. It’s an optimal fit for analysts, marketers, and developers who want “scraping as a service” without building infrastructure.
The platform supports up to millions of requests per month and more than 200 concurrent requests. Enterprise plans add dedicated resources and SLAs.
ScrapingBee uses application programming interface credits–the higher the tier, the more requests and the higher the service level.

Browse AI is a solution for automated data collection and monitoring aimed at business teams that need rapid rollout without DevOps overhead or infrastructure setup.
Key features:
Among data scraping tools, Browse AI stands out for ease of deployment and minimal configuration, making it ideal for automated data extraction. You can get started in minutes: create a robot, set a schedule, and connect enterprise systems. The architecture supports parallel execution of hundreds of processes, automatic scaling, and resource balancing for stable operation as load grows. Projects with strict SLAs can use dedicated compute resources and enhanced resilience parameters.
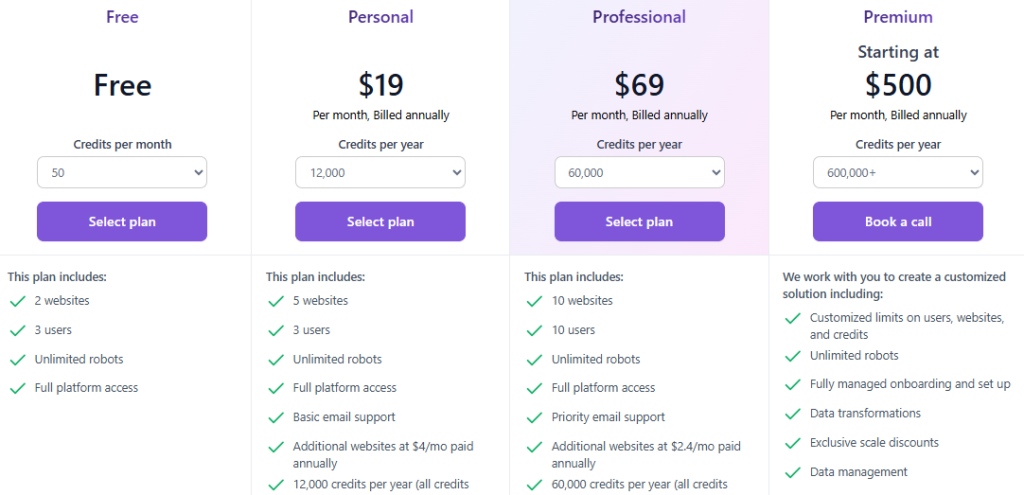
Pricing is credit-based: one credit equals one robot run or one page monitor. This keeps costs transparent and tightly controlled because companies pay for actual usage.

Web Scraper.io is a user-friendly hybrid platform for visual web scraping that combines a browser extension with the Web Scraper Cloud service.
Key features:
Work starts in the browser extension, where you configure scenarios and extraction logic visually. Execution and scaling then move to Web Scraper Cloud, which provides distributed processing, scheduling, and result storage. This approach reduces DevOps load and helps teams move quickly from prototypes to production.
The platform’s infrastructure supports parallel tasks, automatic proxy rotation, and retry mechanisms for resilience under network issues. TLS encryption is used for protection. Entry-level users work in a shared environment, while Enterprise customers get dedicated resources, network-policy control, and extended management through individual agreements.
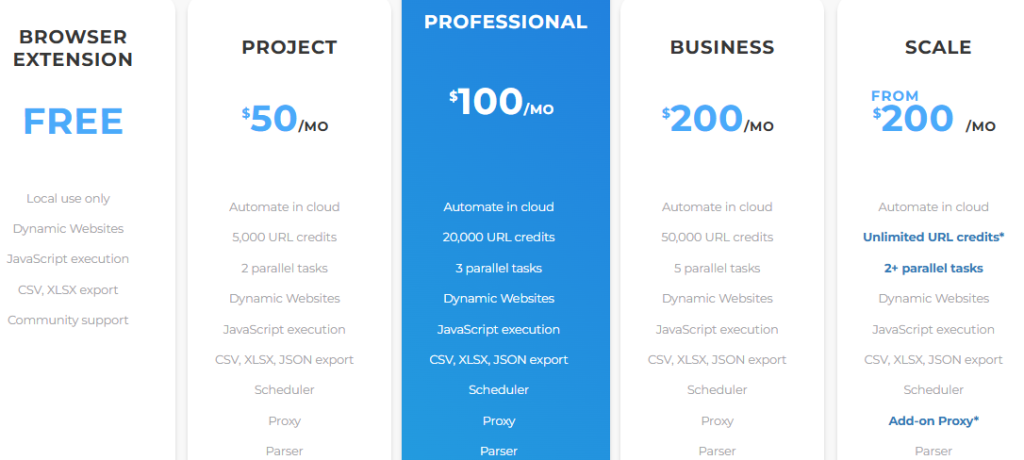
Billing is based on URL credits, where one credit equals one processed page. This model keeps costs transparent and predictable, which is useful when scaling projects.
The market offers a broad spectrum–from simple no-code platforms for SMBs to enterprise-level API platforms with full SLAs, DevOps integrations, and dynamic-content support.
Before choosing a data scraping tool, consider whether your scraping is one-off or systemic, your speed and stability requirements, whether you need to manage proxy infrastructure, and how critical data security is. The comparison table below helps evaluate key parameters of the featured solutions and select the optimal tool for your tasks and scenarios.
| Tool | Type | Primary Use Cases | Scalability | Proxy & CAPTCHA Handling | Dynamic Content | API / Integrations (exact) | SLA | Pricing |
|---|---|---|---|---|---|---|---|---|
| Octoparse | No-code (desktop + cloud) | E-commerce data collection, price & content monitoring, marketing, competitive analysis | Medium (up to 40+ threads) | Yes (limited custom tuning) | JS/AJAX | REST API (Data/Task); export: Google Drive, Amazon S3, Dropbox (v8.7.4+); iPaaS: Zapier, Make | Partial (tiers above Standard) | By volume / parallel process limits |
| Bright Data | Enterprise SaaS | Enterprise-grade data collection, BI, fintech, market analytics | Very high (millions of connections) | Yes (own proxy network; handles anti-bot challenges incl. CAPTCHA/JS checks) | JS/AJAX | Web Unlocker; REST API; SDKs: JavaScript/Node | Yes | Pay-per-record / by collected volume |
| ParseHub | No-code (desktop + cloud) | Marketing, SEO, review analysis, content monitoring, e-commerce tracking | Medium (limits on processes/pages) | Yes (limited custom tuning) | JS/AJAX | REST API v2 (start/status/export); Webhooks; export JSON/CSV; iPaaS | Partial (tiers above Standard) | By pages and processes |
| Oxylabs Web Scraper API | API-first SaaS | DataOps & DevOps integrations, real-time collection, ETL & BI systems | Very high (millions of requests) | Yes | JS/AJAX | REST API (real-time/async); SDK: Python; delivery to S3/GCS/OSS; Webhooks | Yes | Pay-per-success |
| Scrapy | Open-source Framework (Python) | Engineering-grade crawling, ETL pipelines, data processing & analytics | Unlimited (clustering) | Yes | Via Splash/Playwright | Feed exports (CSV/JSON/XML) to S3/FTP/local; pipelines/hooks | No | Free |
| Beautiful Soup | Open-source Library (Python) | Extraction & structuring, Python parsing, small projects & research | Low (with external orchestrators) | Via Python scripts | Via Selenium/Playwright | Python API; commonly with Requests/lxml | No | Free |
| Apify | Low-code / SDK SaaS | E-commerce, SEO, real estate, social networks, automation & low-code scenarios | Very high (auto-scaling) | Yes (Enterprise only for private pools) | Via headless solutions | REST API; clients: JS/Python; export: S3, BigQuery, GDrive; iPaaS: Zapier/Make/n8n | Yes | Compute Units (CU) |
| ScrapingBee | API SaaS | Automated scraping, analytics, marketing, dev without infrastructure | High (~200 parallel by default) | Yes | JS/AJAX | HTML/Browser; REST API; SDK: Node; iPaaS: Make/Zapier | Partial (tiers above Business) | API credits |
| Browse AI | No-code SaaS | Monitoring and data collection without code, business-process automation, change tracking | Medium (hundreds of robots) | Yes | JS/AJAX | REST API v2; Webhooks; iPaaS: Zapier/Make/n8n | Partial (tiers above Professional) | Credit-based runs |
| Web Scraper.io | Hybrid (extension + cloud) | Marketing, training, content monitoring, visual extraction scenarios | Medium (cloud jobs) | Yes (Enterprise only for private controls) | JS/AJAX | Web Scraper Cloud; REST API; Webhooks; SDK: Node/PHP; export: CSV/XLSX/JSON; Dropbox/Sheets/S3 | By agreement | URL credits |
Yes–when collecting information from open and publicly available sources. Ethical use depends on adhering to privacy rules and process transparency. For more on safe practices, see the linked resource.
Tools will continue moving toward API-first designs, automated real-time processing, and AI-driven analytics. Expect stricter requirements around SLAs, security, and source transparency, reinforcing these technologies’ place in enterprise ecosystems.
Safety depends on: proxy strategy and IP rotation, TLS encryption, request monitoring, and adherence to privacy standards (GDPR, SOC 2).
 Instagram
Instagram  Facebook
Facebook  TikTok
TikTok  Telegram
Telegram  YouTube
YouTube  Twitter
Twitter  Tinder
Tinder  Reddit
Reddit  LinkedIn
LinkedIn  Runescape
Runescape  Dofus
Dofus  Metin2
Metin2  Silkroad
Silkroad  Margonem
Margonem  Minecraft
Minecraft  Lineage 2
Lineage 2  WoW
WoW  Lords Mobile
Lords Mobile  Travian
Travian  Steam
Steam  Origin
Origin  Google
Google  ScrapeBox
ScrapeBox  Amazon
Amazon  Ebay
Ebay  Shopify
Shopify  Etsy
Etsy  Netflix
Netflix  Spotify
Spotify  Twitch
Twitch  Browsing
Browsing 





















































